Comparing OpenAI's and Anthropic's Agentic Data Stacks
Months apart, OpenAI and Anthropic each published how they built an internal data agent — different companies, different stacks, no shared roadmap. They converged on the same seven-part architecture. The one place they split — whether a governed semantic layer sits underneath — is the most instructive part, and the proof they arrived there independently.
Months apart, the two labs with the most to say about what AI can do published the same internal memo from opposite coasts. OpenAI went first, early in 2026: Inside our in-house data agent. Anthropic followed on June 3: How Anthropic enables self-service data analytics with Claude. Neither is a product launch. Both are a data team showing its work — how it got a language model to answer real business questions over a real warehouse without quietly making things up.
They share no code, no roadmap, no incentive to agree, and they wrote half a year apart. The design space is as open as any in software right now. And they described the same thing.
That is the takeaway. Not that data agents are good — that two of the most capable engineering organizations alive, working separately and months apart, arrived at the same seven-part architecture. When the search space is wide and the answers converge across that distance, the convergence is signal, not zeitgeist. It means the shape isn't a preference or a passing fashion — it's the structure of the problem. And the one thing they disagree on, as we'll see, is the proof they didn't simply copy each other.
The seven things they both built
1. The bottleneck is context, not SQL. Anthropic states it as a near-theorem: "our ability to map a user's question to specific and up-to-date entities in our data model and know the correct way of working with them. If we can do that, then the resulting execution and SQL becomes trivial." OpenAI says it plainer: "Without context, even strong models can produce wrong results." Both spent their hardest engineering not on query generation — that part is easy now — but on the layer that tells the model which table, which filter, which definition.
2. A human owns the definitions. Anthropic tried to skip this — bootstrapping a semantic layer by having an LLM auto-generate metric definitions. It "produced plausible-looking definitions that encoded the very ambiguities we were trying to eliminate," and was net-negative on their evals. Their rule: "generating the documentation with Claude, but having a human own the definition." OpenAI's second context layer is the same instinct — "curated descriptions of tables and columns provided by domain experts, capturing intent, semantics, business meaning, and known caveats." Neither lab lets the model define its own ground truth.
3. A memory loop that learns from corrections. OpenAI keeps a memory layer whose job is "to retain and reuse non-obvious corrections, filters, and constraints that are critical for data correctness but difficult to infer." Anthropic runs a scheduled agent that "scans stakeholder channels every few hours for … correction language, drafts a one-line fix to the relevant reference doc, and opens a PR." Same closed loop: a human correction becomes durable system knowledge.
4. Evals as continuously-running tests. OpenAI's evals are "like unit tests that run continuously … as canaries in production." Anthropic stores every eval run as warehouse telemetry — "the skill version, git SHA, model ID, per-assertion pass/fail, token count, and wall-clock" — so "did that change help?" becomes a query. Both treat answer accuracy as something you measure constantly, not something you hope for.
5. Provenance on every answer. OpenAI "exposes its reasoning process … links directly to the underlying results, allowing users to inspect raw data and verify every step." Anthropic appends a footer naming "which source tier it came from (semantic layer › curated reference › raw table), how fresh the underlying data is, and who owns the model." Trust is traceability, in both houses.
6. MCP is the front door. OpenAI reaches users "in the Codex CLI via MCP, and directly in OpenAI's internal ChatGPT app through a MCP connector." Anthropic serves its skills "directly as resources over MCP." The protocol Anthropic published the year before is the connector both labs — and the field — now route through.
7. Guide the goal, not the path. OpenAI's second lesson: "highly prescriptive prompting degraded results … rigid instructions often pushed the agent down incorrect paths." Anthropic writes reference docs with "explicit routing triggers … without prescriptive recipes that go stale." Both learned the same thing the hard way: over-script an agent and you make it worse.
Seven for seven. Two teams, months apart, the same architecture.
The one place they split
There is exactly one load-bearing disagreement, and it is the interesting part.
Anthropic puts a governed semantic layer at the center. Its agents are "structurally required (by skill instruction) to leverage the semantic layer first" — a compiled set of metric and dimension definitions, so a question about "weekly active users" resolves to one governed number, "the same number every other surface in the company produces."
OpenAI has no semantic layer at all. Its agent generates SQL over raw tables — one example query runs "180+ lines" — graded in evals against "a manually authored 'golden' SQL query." In place of a compiled metric layer, OpenAI built six layers of context: table-usage signals, human annotations, a Codex pass that derives meaning from the pipeline code, an institutional-knowledge index over Slack and Notion, a memory store, and live runtime queries — aggregated daily into embeddings and pulled in at question time via retrieval.
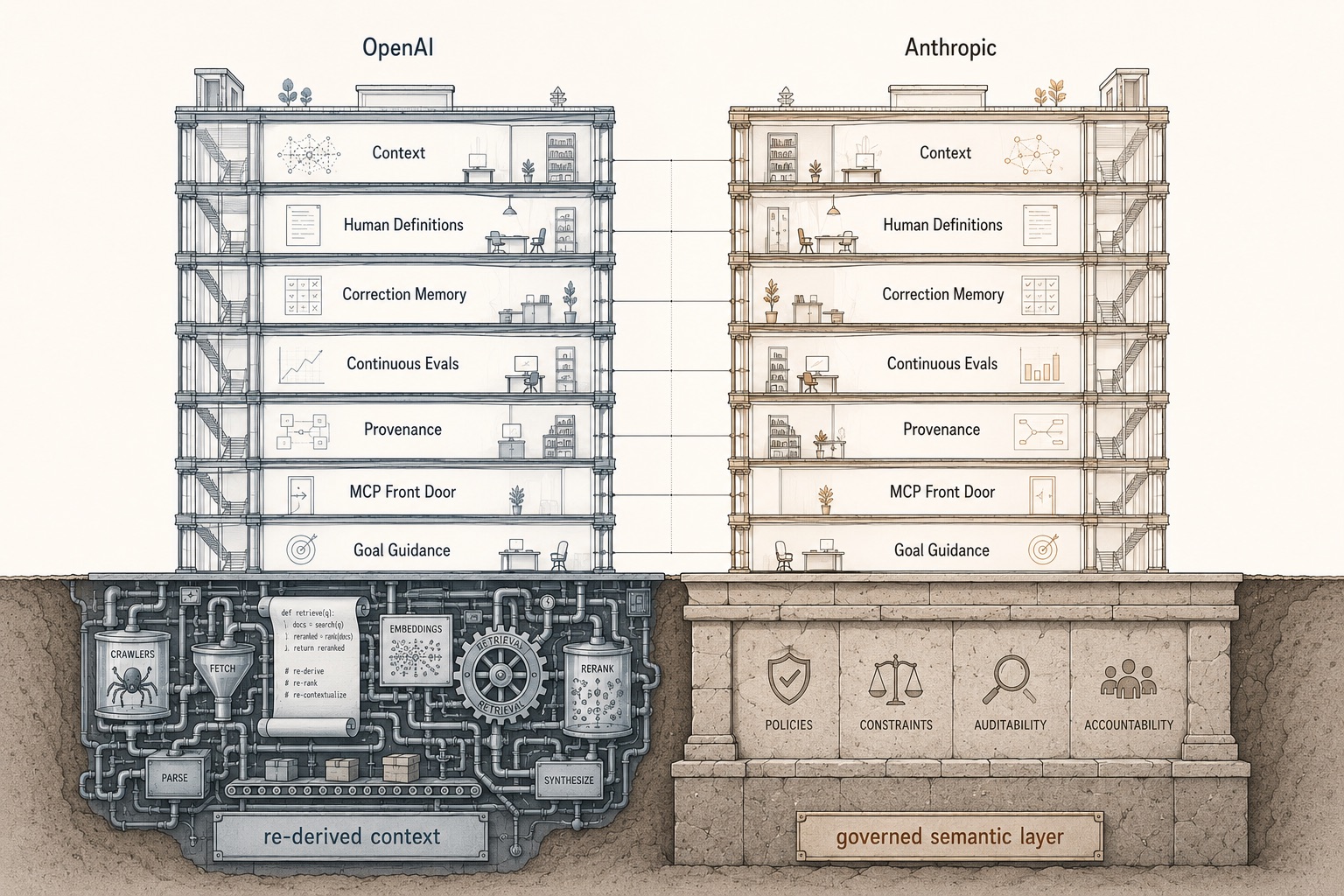
At first glance that looks like a contradiction: one lab says you need the governed layer, the other shipped a 3,500-user agent without it. But read what OpenAI actually built and the contradiction dissolves. They didn't skip governance. They rebuilt it as something far more expensive — a daily enrichment pipeline, a code-crawler, an embedding store, a memory service — because they are OpenAI, and they have the models and the engineering to spend. Their third lesson gives it away: "Meaning Lives in Code." Their agent reads the pipeline that builds each table because "its true meaning lives in the code that produces it." That is the semantic layer's job — encoding what a number means — done by crawling code nightly instead of by maintaining compiled definitions.
So the split isn't whether to govern meaning. Both govern it. The split is where the governed meaning lives: in a compiled semantic layer you maintain (Anthropic, and anyone running dbt), or in a bespoke context-engineering stack you re-derive every night (OpenAI). For a team that already has a semantic layer, Anthropic's path is the one already paid for. For a team with OpenAI's resources and 70,000 tables, building the bespoke stack may be the only path that scales. Same destination, two roads, chosen by what you already own.
And that disagreement is the tell. If Anthropic's June post were merely echoing OpenAI's from five months earlier, it would echo the whole stack. Instead the two match on everything around the question and split on the single most consequential layer — where governed meaning lives. That is exactly what independent teams solving the same problem with different resources look like: same shape, different material. Convergence you could explain by copying isn't evidence of anything. Convergence with a principled disagreement at its center is.
There is a quieter tension underneath, too. OpenAI leans hard on retrieval — RAG over embedded context is the spine of its system. Anthropic's single most useful experiment was a negative one: it gave an agent raw retrieval over thousands of prior queries, confirmed the agent read them, and watched accuracy move "by less than a point." The information was present, seen, and unused; the bottleneck "wasn't access … it was structure." The two aren't quite contradicting — OpenAI retrieves over curated, enriched context, not raw logs, and both agree raw query history alone is weak. But the postures diverge: OpenAI bets that better retrieval over richer context wins; Anthropic bets that better structure over governed metrics wins. That is the live question the next year of this field will answer.
Why convergence is the story
A year ago "AI data agent" meant a chatbot pointed at a warehouse. What has happened since is not that the models got better at SQL — they did, and it turned out not to be the constraint. What happened is that the architecture around the model settled. Independently, the two labs best positioned to find a shortcut found the same non-shortcut: govern the meaning, keep a human on the definitions, close the correction loop, measure accuracy like a test suite, cite your sources, and stop over-scripting.
That settled shape is good news for everyone who isn't OpenAI or Anthropic. It means the reference architecture is now legible — you can read these two posts and know what to build. And it means a team that already runs a governed semantic layer is not behind the frontier on the expensive part. It is standing on the same foundation both labs spent their hardest engineering to construct; the remaining distance is the measurement layer — the evals-as-telemetry, the drift detection, the provenance footer — that both labs treat as core and most teams haven't built yet.
The frontier even agrees on what's still unsolved. Anthropic names it directly: the failure mode none of the machinery fully catches is "the silent one" — the answer that is wrong, looks right, and gets used. "We don't have a robust solution yet." Two labs converged on the same architecture and the same open problem. When the disagreements are this small and the open question is this shared, the field has stopped guessing at the shape and started building it.
- The numbers are self-reported. Anthropic's "~95% of queries automated at ~95% accuracy" and OpenAI's adoption figures are vendor claims in vendor posts. The architectures are first-party and credible; the scorecards are marketing-adjacent. Read the shapes, not the percentages.
- Convergence isn't fully independent. Both ride the same ecosystem — MCP, the dbt/warehouse world, a shared discourse — so some of the "same shape" is a common substrate, not two blank-slate derivations. The independence claim is strongest on the layers where they actually had a choice (semantic layer, retrieval posture) and weakest on the ambient ones (MCP as a front door).
- One post predates the other by months. OpenAI's came first; Anthropic's could in principle have absorbed it. The semantic-layer split is the main reason to read this as convergence rather than influence — but it is an inference, not a proof.
- "Same destination" understates the cost gap. OpenAI's bespoke context stack and a maintained dbt semantic layer reach governed meaning by very different amounts of work. For most teams that difference is the whole decision, and this piece treats it as a footnote.
trust=untrusted-source vendor posts per the workspace rule; all quotations were taken verbatim and the publication dates verified against the source pages (the two posts are roughly five months apart, not the same week). This article is trust=synthesis — librarian-authored, grounded in a close read of both posts, continuing the arc of The Exhaust Brain and the Modeled Brain and Which Graph Goes Under the Brain?